
DKD论文总结
Decoupled Knowledge Distillation 论文精读总结
Title
Decoupled Knowledge Distillation CVPR 2022
Summary
将KD loss拆分成TCKD(二值概率)以及NCKD(多值概率),并探究了KD loss存在的局限性,提出了DKD方法
Research Objective
性能最好的蒸馏方法都是基于中间层特征的蒸馏,这类方法不够完美:会引进额外的计算量和内存消耗。直觉上,基于logit的方法相比基于feature在更高的语义层面,因此它应当与基于features具有相当的性能。
Problem Statement
通过将KD的loss拆分成TCKD与NCKD,探究发现:
- 首先,NCKD loss项的权重大小与Teacher模型对样本目标类的置信度负相关,事实上,teacher模型置信度越高的样本,应该具有更可靠以及更有价值的知识
- 其次,TCKD与NCKD权重高度耦合,TCKD与NCKD的权重应该被分别考虑
Method(s)
两个工作:
- 通过重写KD loss,将KD拆分成TCKD与NCKD,同时通过实验证明了两个因子对性能的影响:
- TCKD迁移了有关于训练样本学习难度的知识,并且训练样本越难被学习,TCKD的价值越高:通过数据增强,噪声标签以及使用imagenet三个方法来实现对猜想的验证。
- NCKD是基于logit方法能够工作的核心原因,但它的作用被压制了,NCKD在具有更高置信度的样本上能蒸馏出更有价值的知识:解耦实验,只用NCKD就可以超过student模型并且与baseline KD性能相当;将训练样本拆分为置信度高的与置信度低的两组,通过NCKD分别在两个数据集上蒸馏,发现置信度高的数据集能迁移更多知识
- 基于TCKD与NCKD的拆分公式,将TCKD的权重置为超参数,NCKD的权重由teacher模型的置信度改为超参数,从而解决高耦合的问题。
Evaluation
通过设计巧妙的实验验证所有的猜想:
基于TCKD与NCKD拆分后的实验效果,猜想TCKD与NCKD的作用
- 通过降低Teacher模型的置信度,验证TCKD表示的是样本的学习难度,且越难学习的样本,TCKD越有效
- 通过拆分数据集,验证NCKD对具有更高置信度的样本能够迁移更多知识
通过对超参数的搜索验证方法的有效性
-
对分别进行超参数搜索,得出TCKD与NCKD前的权重都是有必要的,即需要对KD loss实现解耦合
-
主实验结果增加了别的领域(目标检测)的数据集测试
设计许多额外实验,证明方法的强大
-
将与基于feature的方法及base lineKD作对比,DKD训练效率最高(准确率,训练时间,参数量)
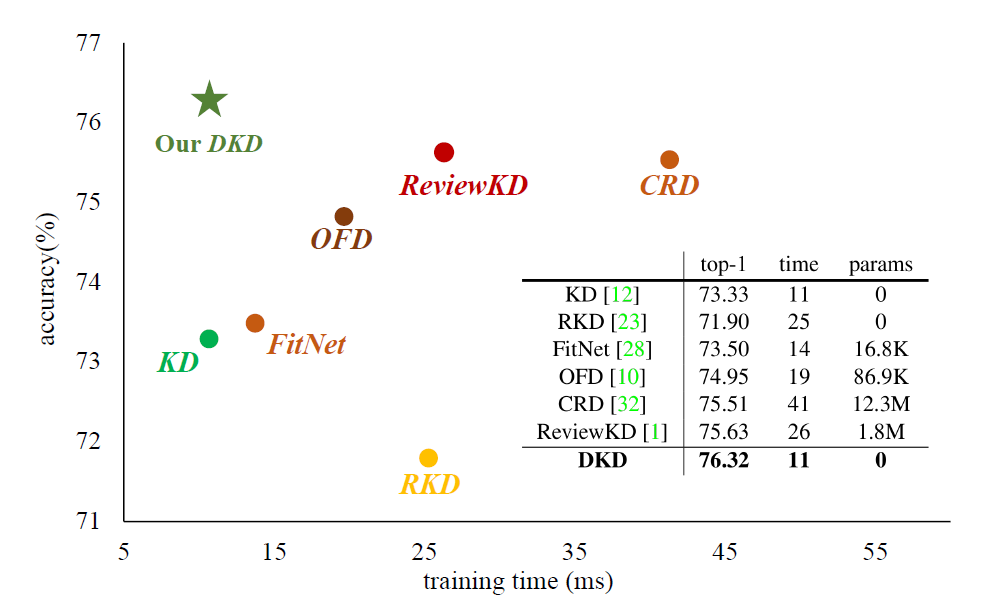
-
缓解大参数量的teacher模型不能很好地蒸馏的问题
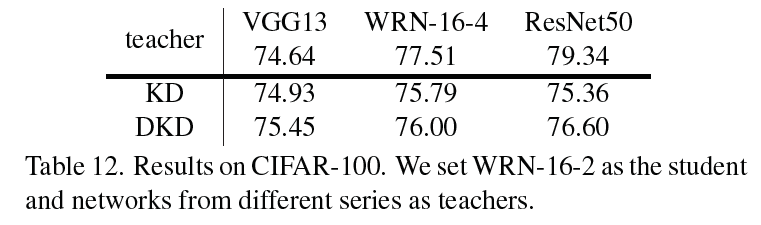
-
知识迁移能力(特征迁移)
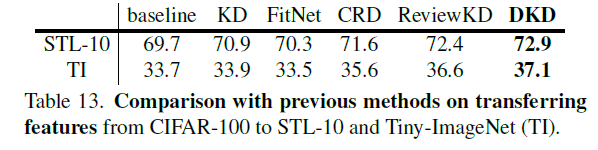
-
可视化:特征区分度,logits与teacher的差异

-
Conclusion
作者给了哪些strong conclusion, 又给了哪些weak conclusion?
- 将KD loss重写为TCKD与NCKD,两部分都会影响蒸馏效果
- baseline KD loss约束了知识蒸馏的灵活性和有效性
- 提出了DKD方法
- 局限性:DKD方法不是性能最好的,DKD的超参数缺少足够研究
Notes
- 实验
- 超参数与样本关联而不是数据集
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 MEMORANDUM!
评论