
Channel-Wise Attention 论文阅读
Channel Distillation:Channel-Wise Attention for Knowledge Distillation 论文精读总结
Title
Channel Distillation: Channel-Wise Attention for Knowledge Distillation
Summary
文章核心内容:将通道测的注意力分布作为知识迁移给学生模型
文章缺点:消融实验太少,无法提供有力证据支撑前面的猜想
Research Objective
通过知识蒸馏的方法得到准确度高、参数量小 的学生模型
Problem Statement
- the teacher is not good enough, and the student cannot accurately learn the essential information from the teacher.(学生模型无法准确学到教师模型的知识)
- if the teacher is not completely correct, during training, ifthe student makes a decision with reference to the decisive result of the teacher, the poor output of the teacher will have a bad influence on the student instead.(教师模型准确率不是百分之百,错误样本会误导学生模型)
- there is a margin betweenthe teacher and the student since they have different structure, which will make the student unable to find its own optimization space if we always let the teacher supervise it.(学生模型与教师模型网络结构的不同,导致它们具有不同的参数空间,因此不能一直在教师模型的监督下学习)
Method(s)
-
利用注意力的机制迁移通道信息:
Channel Distilltaion-
SENet注意力机制:
-
CD Loss:
-
-
Guided Knowledge Distillation-
原始KD:
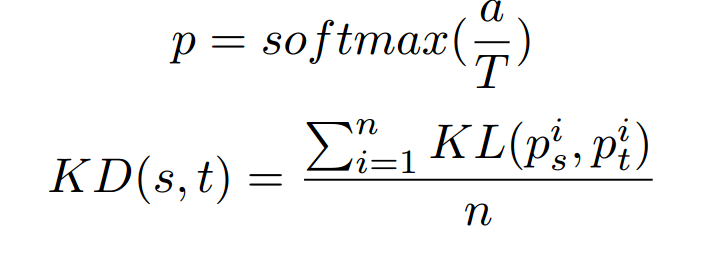
-
GKD:
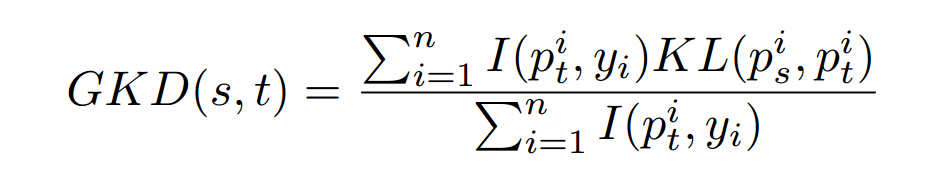
-
-
Early Decay teacher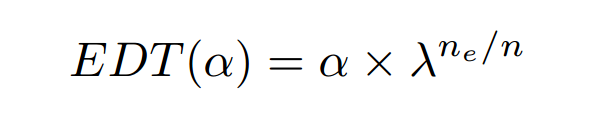
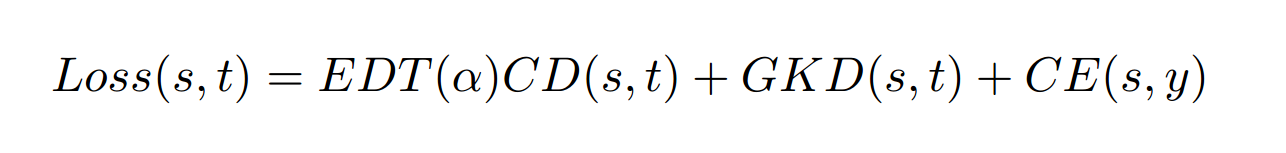

Evaluation
作者如何评估自己的方法,有没有问题或者 可以借鉴的地方。
指标:Top1 error 、Top5 error
网络:Resnet34(Teacher)、Resnet18(Student)
问题:没有图、分析不够
Conclusion
transfer the channel attention information from the teacher to the student, not just mimicking the teacher’s representation in label.
Notes
- 除了CD,另外两个idea都可以与别的方法结合起来,是否会比本文的CD更好
- 通道知识迁移,与标签知识迁移同时进行,与已有的工作:通过注意力机制的特征图迁移隐层参数,再作标签知识的迁移。哪种更好
- 既然有Teacher模型,为什么不利用Teacher对未监督数据做数据增强
- 原理图简陋
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 MEMORANDUM!
评论